Bien,si han usado algun tipo Unix a de alguna forma rara o libre un tipo Unix conoceran las tuberias,o pipes Unix de comunicacion,pues esa tuberia es de solo dos lados,entrada y salida,pues bien si conocen los tubos en fotma de T sabran que tienen tres salidas,pues es eso lo que hace el comando tee,combierte nuesta tuberia en una T:

Bien,como vemos en la imagen de arriba lo que hace es tomar el primer comando meterlo en un archivo y luego continuar con el siguiente comando:
Por ejemplo:
Bien,esto es lo que haria el flujo estandar de Unix:
Si queremos que haga esto:
Tenemos que añadir -a a tee:
Por ejemplo

Leer más...
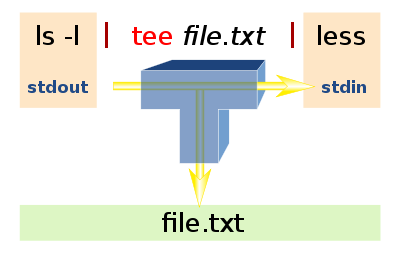
Imagen de : wikipedia
Bien,como vemos en la imagen de arriba lo que hace es tomar el primer comando meterlo en un archivo y luego continuar con el siguiente comando:
Por ejemplo:
wget -O- http://www.pagina.com/dvd.iso | tee dvd.iso | sha1sum > dvd.sha1
Bien,esto es lo que haria el flujo estandar de Unix:
>
Si queremos que haga esto:
>>
Tenemos que añadir -a a tee:
Por ejemplo
ls ~/Descargas | tee archivos_selectos.txt | less && echo "Documentos : " >> archivos_selectos.txt; ls ~/Documentos | tee -a archivos_selectos.txt | less

Y con esto nos guarda los archivos de Descargas en un archivo,nos los muestra con less,y hace lo mismo con los archivos de Documentos sin rescribir todo el archivo.
También podemos añadir el parametro -i,que lo que hace es que ignore la señal SIGINT,el usado ctrl+c.
Referencia : wikipedia